- Ollama permite ejecutar modelos de IA avanzados en local sobre Windows 11, con privacidad total y sin depender de la nube.
- La nueva app gráfica para Windows facilita usar modelos sin tocar la terminal, aunque algunas funciones avanzadas siguen en CLI.
- Es compatible con CPU modernas y GPUs NVIDIA y AMD, y permite mover la carpeta de modelos a otro disco si hace falta espacio.
- Desde Windows puedes usar modelos como DeepSeek, Llama o Mistral vía chat, consola o API local en http://localhost:11434.
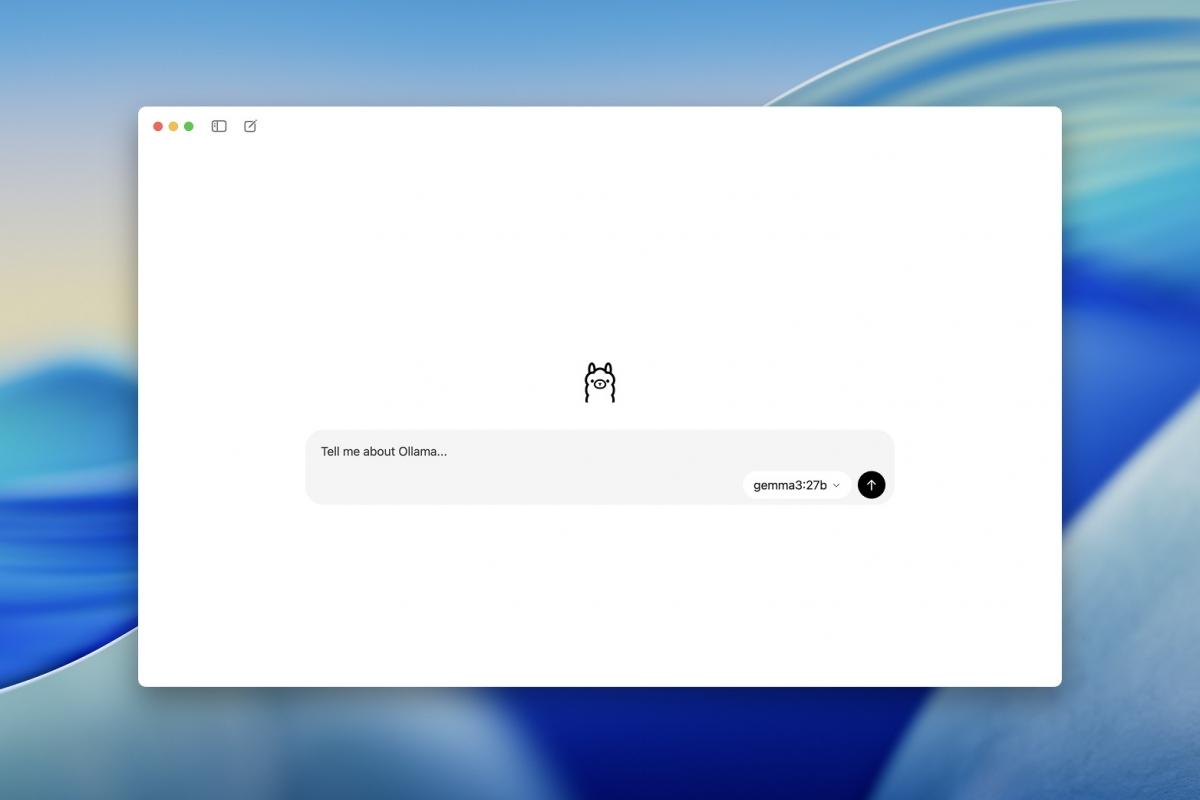
Si te gusta cacharrear con modelos de inteligencia artificial en tu propio PC y no depender de servicios en la nube, Ollama se ha convertido en una de las opciones más interesantes para Windows 11. Hasta hace poco estaba muy centrado en la línea de comandos, pero ahora cuenta también con una aplicación gráfica oficial que hace que cualquiera pueda empezar a usarlo sin miedo a la consola.
La gran ventaja de Ollama en Windows 11 es que te permite descargar y ejecutar modelos de lenguaje de forma local (como DeepSeek, Llama, Phi, Mistral, Qwen, Gemma o Llava) manteniendo tus datos en tu ordenador. Además, la nueva app para Windows se integra con la bandeja del sistema y el menú de inicio, haciendo que usar IA generativa en tu equipo sea casi tan sencillo como abrir cualquier otro programa de chat.
Qué es Ollama y por qué interesa tanto en Windows 11
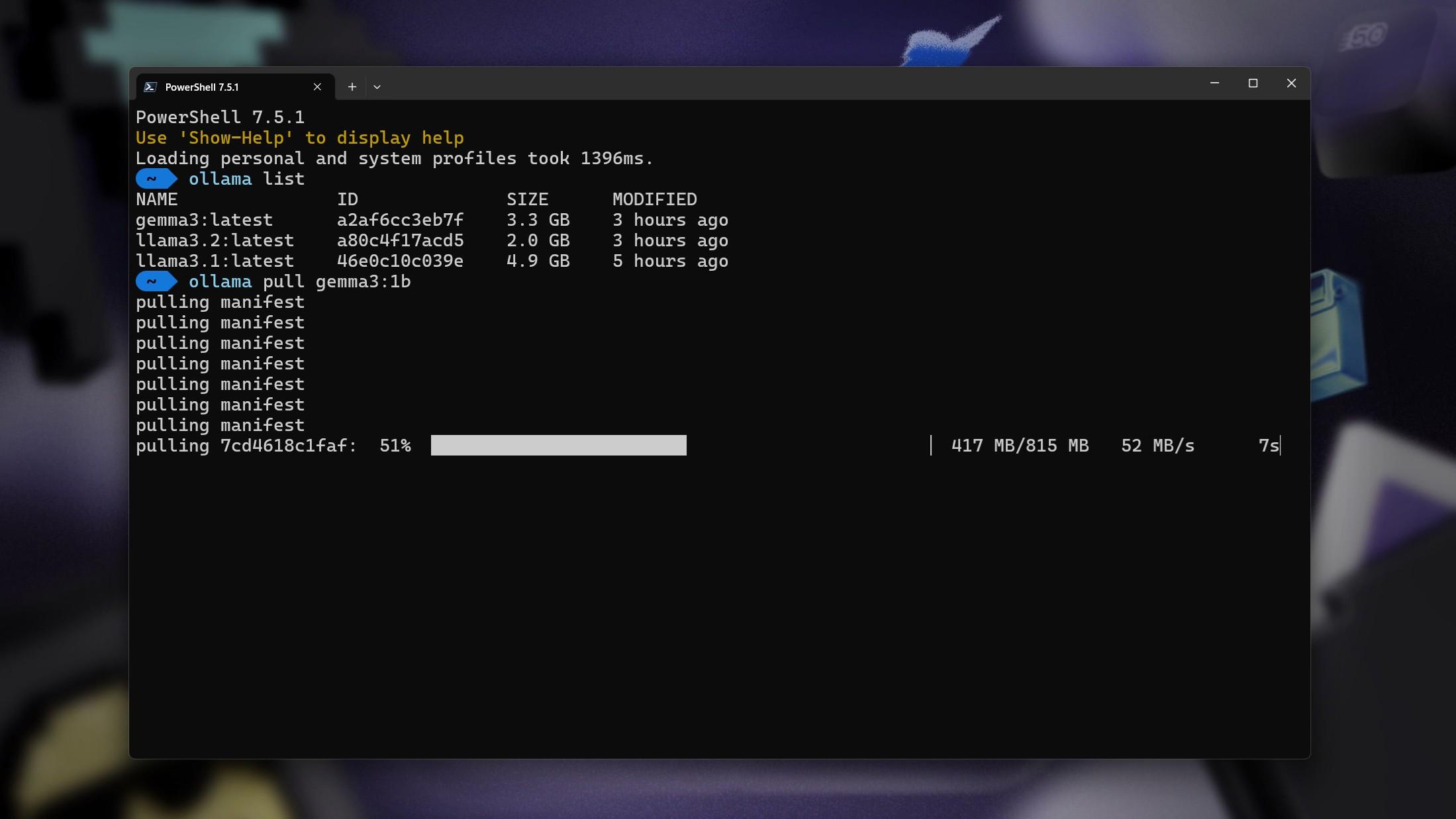
Ollama es un cliente de modelos de inteligencia artificial que puedes instalar en Windows, macOS y GNU/Linux. Su función es servir como base para ejecutar distintos modelos de lenguaje (y multimodales) directamente en tu máquina. No es un único chatbot, sino una especie de gestor y motor que descarga, ejecuta y orquesta esos modelos.
Una de sus características clave es que todo funciona en local: en lugar de conectarte a la web de una empresa para hablar con su IA, el modelo reside en tu PC. Esto tiene varias implicaciones importantes: tus consultas no se suben al servidor de terceros, el uso no depende de que haya conexión a Internet y se reducen posibles filtros o restricciones impuestas en algunos servicios online. A cambio, claro, no puede hacer búsquedas en la red durante las conversaciones salvo que lo conectes tú a otras herramientas.
Ollama se puede manejar tanto desde la terminal como desde una interfaz gráfica. La versión clásica se apoyaba completamente en la consola (Símbolo del sistema, PowerShell o cualquier otro terminal), donde escribes los comandos para instalar modelos, ejecutarlos y enviar tus prompts. Ahora, con la llegada de la app nativa para Windows, muchas de estas acciones se pueden hacer con unos cuantos clics, sin escribir ni una sola orden.
En cuanto a los modelos compatibles, Ollama ofrece un catálogo muy completo accesible desde su buscador en la web oficial. Ahí puedes encontrar diferentes familias (DeepSeek, Llama, Mistral, Phi, Qwen, Gemma, Llava, etc.) con distintas variantes y tamaños. Cada una aparece con instrucciones de uso, incluyendo el comando que necesitas para descargarla y ponerla en marcha en tu equipo.
La filosofía de Ollama gira alrededor de tres pilares: privacidad, control y flexibilidad. Tú decides qué modelos instalar, dónde se almacenan en tu disco y cómo se integran con tus flujos de trabajo (terminal, app gráfica o API). Esto lo hace muy atractivo tanto para usuarios curiosos que quieren probar IAs modernas, como para perfiles más técnicos que buscan incrustar estos modelos dentro de sus propias aplicaciones.
Nueva aplicación gráfica de Ollama para Windows 11

Una de las grandes novedades recientes es que Ollama ahora cuenta con una interfaz gráfica oficial para Windows 11. Hasta hace nada, todo pasaba por escribir comandos en la consola, algo que a muchos usuarios les echaba para atrás. Con esta app, puedes abrir Ollama desde el menú de inicio o desde el icono que aparece en la bandeja del sistema, y trabajar con IA casi como si fuera un chat convencional.
La aplicación gráfica se instala junto al componente de línea de comandos, de modo que en realidad tienes las dos formas de uso disponibles a la vez: interfaz visual para lo habitual y CLI para operaciones más avanzadas. Tras la instalación, Ollama se ejecuta en segundo plano y mantiene un servidor local que atiende tanto las peticiones de la app como las de la API y el terminal.
Desde la propia ventana de la aplicación puedes seleccionar el modelo que quieras utilizar, escribir tus preguntas en una caja de texto y ver las respuestas generadas al momento. El comportamiento es muy similar al de cualquier chatbot en la web, con la ventaja de que aquí la IA está corriendo en tu propio hardware, aprovechando tu CPU y, si la tienes, tu GPU.
La app gráfica no se queda solo en texto. Una de sus funciones más interesantes es que permite arrastrar y soltar archivos directamente sobre la ventana para que el modelo los procese. Puedes usar imágenes, documentos de Word, archivos de código y otros formatos habituales, de manera que la IA tenga en cuenta ese contenido a la hora de responderte. Esto facilita muchísimo tareas como analizar documentación, revisar proyectos o comentar capturas.
Además, la aplicación incluye un ajuste para modificar la longitud del contexto, es decir, la cantidad de información que el modelo es capaz de manejar en una misma conversación. Si trabajas con textos extensos o varios documentos, ampliar el contexto es muy útil, aunque implica un consumo de memoria RAM bastante mayor. Es una de esas opciones que te permiten afinar el comportamiento del modelo según la potencia de tu PC.
Pese a todos estos avances, algunas operaciones avanzadas siguen dependiendo de la terminal. Por ejemplo, cargar modelos personalizados, gestionarlos de forma muy granular o ciertos tipos de integración aún pasan por comandos. Aun así, para la mayoría de usuarios la interfaz gráfica simplifica muchísimo la experiencia diaria, porque el uso habitual (elegir modelo, chatear, añadir archivos) se hace a golpe de ratón.
Requisitos y compatibilidad de Ollama en Windows 11
Ollama funciona como aplicación nativa en Windows, con soporte para GPUs NVIDIA y AMD Radeon. A diferencia de soluciones que obligan a montar entornos virtualizados o WSL para todo, aquí el instalador se integra directamente en el sistema y te deja usar la herramienta desde el menú de inicio, el icono en la bandeja y cualquier terminal de Windows (cmd, PowerShell o el que prefieras).
Los requisitos oficiales de sistema parten de Windows 10 22H2 en adelante, tanto en la edición Home como en la Pro, por lo que Windows 11 entra de lleno en lo soportado. Para aprovechar la aceleración por GPU, se recomienda contar con drivers relativamente recientes: a partir de la versión 452.39 en el caso de tarjetas NVIDIA, y los controladores adecuados para tu modelo Radeon si tienes una AMD.
A nivel de hardware, conviene disponer de un procesador moderno con soporte para AVX-512 y al menos 16 GB de memoria RAM si pretendes ejecutar modelos grandes con cierta soltura. No es obligatorio tener una GPU dedicada para poner a funcionar Ollama, pero la diferencia de rendimiento al contar con una gráfica compatible es notable, sobre todo en modelos de mayor tamaño.
En cuanto al espacio en disco, el instalador de Ollama necesita alrededor de 4 GB para los binarios. Sin embargo, donde realmente se nota el consumo es en los propios modelos de lenguaje, que pueden ocupar desde unos pocos gigas hasta decenas, e incluso cientos de gigas dependiendo de la familia y del tamaño elegido. Es importante prever esto antes de volverse loco instalando variantes gigantes en un SSD pequeño.
Un detalle a tener en cuenta es que Ollama usa caracteres Unicode para indicar el progreso en la terminal. En algunas fuentes antiguas de Windows 10 esos símbolos pueden verse como cuadros vacíos en lugar de barras o iconos. Si te sucede, basta con cambiar la fuente del terminal a alguna más moderna (por ejemplo, Consolas o Cascadia Code) para verlo correctamente.
Instalación de Ollama en Windows 11: opciones y rutas
La forma más sencilla de instalar Ollama en Windows es descargar el archivo OllamaSetup.exe desde su web oficial. En la página principal tienes un botón de descarga que detecta automáticamente tu sistema operativo, aunque siempre puedes seleccionar manualmente el instalador para Windows si estás navegando desde otro dispositivo.
Una vez descargado el instalador, el proceso es prácticamente de siguiente, siguiente, instalar. No necesitas permisos de administrador para completarlo, ya que Ollama se instala por defecto en tu carpeta de usuario. Esto es cómodo en entornos donde no tienes control total sobre la máquina, o si simplemente quieres mantenerlo aislado en tu perfil.
Además del instalador estándar, existe una versión en formato ZIP con solo la línea de comandos: el archivo ollama-windows-amd64.zip. Esta variante está pensada para integraciones más técnicas, para ejecutar Ollama como servicio de sistema o para incrustarlo dentro de otras aplicaciones. Incluye el binario de la CLI y las dependencias necesarias para funcionar con GPU NVIDIA.
Dependiendo de tu hardware, puede que necesites otros paquetes adicionales. Por ejemplo, si quieres usar GPU AMD puedes recurrir al paquete ollama-windows-amd64-rocm.zip, mientras que en entornos que requieren MLX/CUDA existe un archivo dedicado (ollama-windows-amd64-mlx.zip). Todos estos componentes se extraen en el mismo directorio de la CLI, y desde ahí puedes lanzar el servidor con comandos como ollama serve, apoyándote en utilidades como NSSM para levantarlo como servicio en segundo plano.
Para un uso normal en Windows 11, con abrir el ejecutable principal tras la instalación ya tendrás Ollama funcionando en segundo plano. El instalador añade la ruta al ejecutable a la variable PATH de tu usuario, de forma que los comandos ollama estén disponibles directamente desde cmd, PowerShell o cualquier terminal que abras a partir de ese momento.
Gestión del espacio en disco y rutas de modelos en Windows
El instalador de Ollama coloca los archivos principales en la carpeta de tu usuario y utiliza varias rutas internas para binarios, modelos, logs y ficheros temporales. Conocer estas carpetas te facilita resolver problemas, revisar registros o reubicar contenido cuando el espacio en tu unidad principal empieza a escasear.
Los logs y las actualizaciones descargadas se almacenan en %LOCALAPPDATA%\Ollama. Ahí puedes encontrar, por ejemplo, el archivo app.log con los registros más recientes de la aplicación gráfica, server.log con la actividad del servidor y upgrade.log con la información generada durante los procesos de actualización. Esta carpeta es útil si algo no funciona como debería y necesitas echar un vistazo a qué está pasando.
Los binarios principales se sitúan en %LOCALAPPDATA%\Programs\Ollama, carpeta que el instalador añade automáticamente al PATH de tu usuario. Eso es lo que permite que puedas teclear ollama en cualquier terminal sin tener que navegar hasta el directorio concreto donde está el ejecutable.
Los modelos descargados y la configuración de Ollama se guardan, por defecto, en %HOMEPATH%\.ollama. Este directorio es el que más puede crecer a medida que vas añadiendo modelos más grandes al sistema. Si estás usando un SSD pequeño para el sistema operativo y un segundo disco para datos, es muy probable que quieras mover aquí la carpeta de modelos para no comerte el espacio de C:.
Para cambiar la ubicación donde se guardan los modelos, Ollama permite establecer la variable de entorno OLLAMA_MODELS. El proceso es sencillo: abres la aplicación de Configuración de Windows 11, buscas «variables de entorno» y entras en la opción para editar las variables de tu cuenta de usuario. Ahí puedes crear o modificar OLLAMA_MODELS con la ruta de la carpeta en la que quieras que se descarguen y almacenen los modelos a partir de ese momento.
Una vez guardado el cambio, conviene cerrar la aplicación de Ollama de la bandeja del sistema y volver a lanzarla desde el menú de inicio, o bien abrir un nuevo terminal para que recoja la variable actualizada. A partir de ahí, las descargas de modelos irán a la nueva ruta. Además, Ollama utiliza la carpeta %TEMP% para generar ejecutables temporales en directorios con nombre que suele empezar por «ollama», algo normal durante ciertas operaciones internas.
Ollama en WSL, CUDA y problemas frecuentes
Algunos usuarios han intentado instalar y usar Ollama dentro de WSL (Windows Subsystem for Linux) en Windows 11, sobre todo quienes ya tienen su entorno de trabajo montado allí. En varios casos, los fallos que se encontraban no estaban tanto en Ollama en sí como en la configuración de CUDA y los drivers de la GPU dentro de WSL.
Uno de los enfoques que se ha demostrado efectivo ha sido resolver primero la instalación de CUDA correctamente en WSL, siguiendo una guía paso a paso centrada en la compatibilidad de la GPU. Una vez que el soporte CUDA quedaba bien configurado, la instalación de Ollama dentro del subsistema se completaba sin mayores problemas y el rendimiento con GPU pasaba a ser el esperado.
Aunque la experiencia en WSL puede ser muy buena si está bien configurado, la recomendación general para la mayoría de usuarios de Windows 11 es usar Ollama de forma nativa. La aplicación oficial para Windows ya incorpora soporte para GPUs NVIDIA y AMD Radeon, evita lidiar con capas extra y reduce la probabilidad de errores derivados de la virtualización o de drivers mal enlazados.
En caso de que algo vaya mal en la versión nativa de Windows, es muy útil aprovechar las rutas de logs mencionadas antes. Revisar app.log y server.log en %LOCALAPPDATA%\Ollama suele dar pistas claras sobre qué está fallando, ya sea un problema al descargar un modelo, algún conflicto con la GPU, falta de espacio en disco o errores en la configuración de la API.
Cómo instalar y usar modelos de IA en Ollama desde Windows 11
Una vez tengas Ollama instalado en tu equipo con Windows, el siguiente paso es elegir qué modelo de IA quieres utilizar. Para eso lo más cómodo es ir a la página de búsqueda de modelos en la web oficial (ollama.com/search). Desde ahí, puedes navegar por las distintas opciones, ver sus tamaños, descripciones y versiones disponibles.
Al entrar en la ficha de un modelo concreto, verás un selector de versiones y, en la parte superior derecha, el comando necesario para instalarlo y ejecutarlo. Estos comandos siguen una estructura muy sencilla, del tipo ollama run nombre-del-modelo:versión. Un ejemplo típico sería ollama run deepseek-r1:8b para lanzar la variante de 8.000 millones de parámetros de DeepSeek R1.
La primera vez que lances ese comando, Ollama descargará el modelo desde sus servidores y lo dejará guardado en tu carpeta de modelos. Esta fase puede tardar un poco, sobre todo en conexiones más lentas o con modelos de muchos gigas. Una vez completada la descarga, en las siguientes ocasiones el modelo arrancará directamente sin tener que volver a bajarse.
Cuando el modelo está corriendo en la terminal, verás que la línea de entrada cambia y aparece un indicador del estilo >>>. En ese momento todo lo que escribas en la consola se enviará al modelo como prompt, y él responderá directamente en el mismo terminal. Es una forma muy directa de trabajar, sin interfaz de por medio, ideal si te mueves cómodo en consola.
Si prefieres no tocar la línea de comandos, puedes abrir la app gráfica de Ollama desde el menú de inicio y seleccionar el modelo que quieras desde ahí. La lógica por detrás es la misma (el modelo se descarga, se ejecuta en local y procesa lo que le pidas), pero en lugar de teclear verás una ventana de chat con campo de texto, historial y la opción de arrastrar archivos.
Uso de la API de Ollama en Windows y accesos avanzados
Además de la app gráfica y la terminal, Ollama expone una API HTTP local que se sirve por defecto en http://localhost:11434. Esto quiere decir que cualquier programa o script que pueda hacer peticiones HTTP puede comunicarse con el modelo de IA instalado en tu PC, sin salir de tu red y sin depender de servicios externos.
Desde PowerShell, por ejemplo, puedes enviar peticiones a la API para generar texto, obtener respuestas o integrar Ollama en pequeñas utilidades. Esta vía es especialmente interesante para desarrolladores o usuarios avanzados que quieran montar herramientas personalizadas, conectar Ollama a editores de código, automatizar flujos de trabajo o integrarlo con otras aplicaciones de escritorio.
Si has optado por la versión standalone de la CLI y lo ejecutas como servicio con herramientas como NSSM, puedes tener un servidor de modelos siempre disponible en segundo plano, listo para responder a las peticiones de tus aplicaciones. El comando ollama serve se encarga de levantar ese servicio HTTP que luego consumirás a través de la API.
Cuando surgen problemas con la API o con el servidor en general, los archivos server.log y upgrade.log suelen contener la información más valiosa. Revisarlos te permitirá detectar errores de configuración, incompatibilidades con drivers de GPU, fallos en actualizaciones y otros incidentes que pueden afectar al uso avanzado de Ollama dentro de Windows 11.
En caso de que quieras desinstalar completamente Ollama de tu sistema, el instalador para Windows registra un desinstalador en la sección de «Agregar o quitar programas» de la Configuración. Desde ahí puedes eliminar la aplicación, aunque recuerda que la carpeta de modelos en tu directorio de usuario puede seguir ocupando bastante espacio si no la borras o mueves manualmente.
Con todo este ecosistema —interfaz gráfica, terminal y API local— Ollama convierte a Windows 11 en una plataforma muy potente para trabajar con modelos de lenguaje en local. Da igual si solo quieres charlar con una IA en tu PC sin mandar tus datos a terceros, o si planeas integrarla en flujos de desarrollo complejos: la herramienta se adapta a ambos perfiles siempre que cuentes con un hardware razonablemente moderno y un poco de espacio en disco para los modelos que vayas a utilizar.